Share it with your senior IT friends and colleagues
Reading Time: 3minutes
How much computational and memory is required to store the parameters or train a Large Language Model?
Even if you do not know the exact answer, you must be aware that it’s huge, right?
It is so huge that it is beyond the reach of many big organisations, forget about individuals.
So, how can we fine-tune or make an inference on an LLM with limited computational power present at our disposal?
The solution is Quantization.
In this article, let us try to understand the concept in simple language.
Disclaimer – This article assumes that you know about Large Language Models and Fine Tuning. In case you need to be made aware of them then we suggest you should first learn about these concepts.
As the parameter size of LLMs increases, more and more computational power is required to pre-train the model or fine-tune it.
To give you an estimate, a 175 billion parameter model requires 14,000GB of RAM @ 32-bit full precision. This is definitely too large, right?
We need hundreds of GPUs to serve this requirement and it is highly expensive.
For a complete explanation, check out this video
You may say that we anyway do not pre-train LLMs. We directly use them and hence we do not need so much computation.
You are right. However, to fine-tune LLMs or infer LLMs, we still need a good amount of computational power and not many can afford that either.
So, we have to optimize LLMs. There are various techniques to optimize LLMs – Distillation, Quantization, Pruning, etc.
Out of these, Quantization is more popular.
What is Quantization?
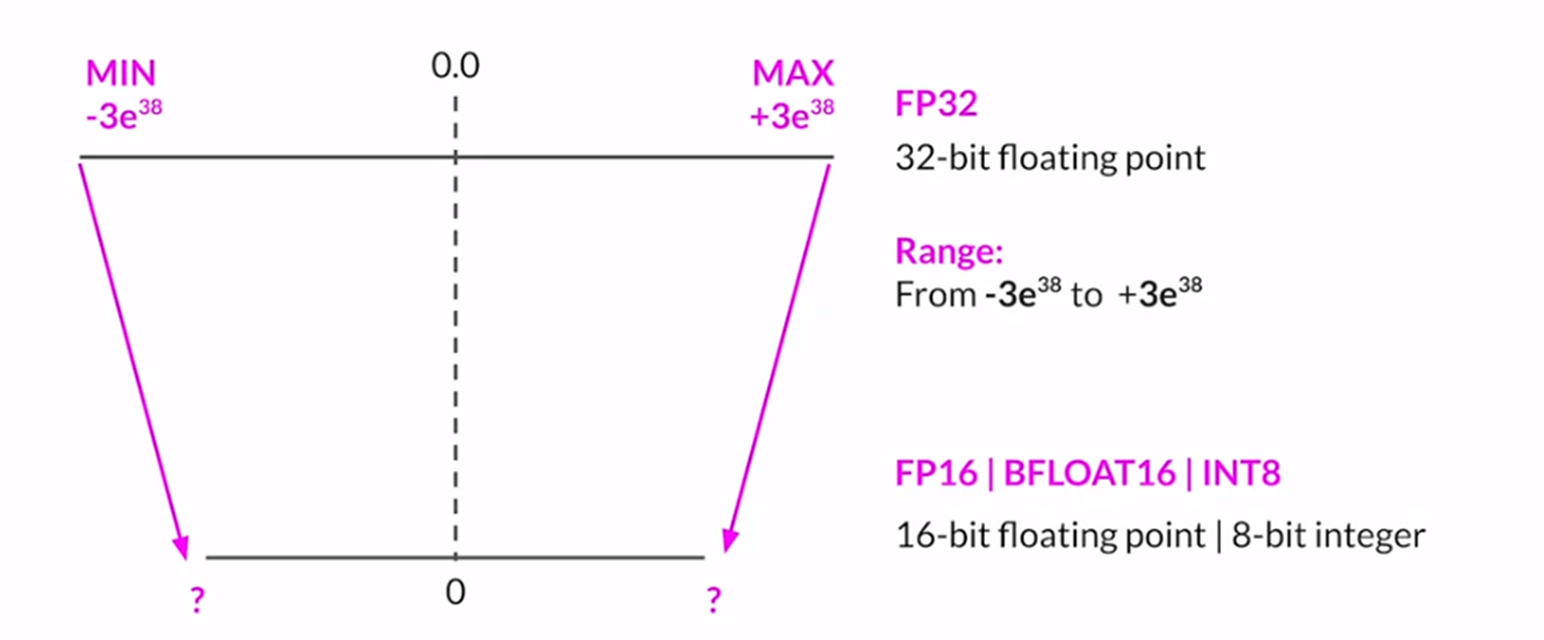
When we store the weights and parameters of an LLM, we store them in a 32-bit floating point.
In 32-bit floating point precision,
1 bit is for sign
8 bits are for exponent, and
And the remaining 23 bits to store the fraction
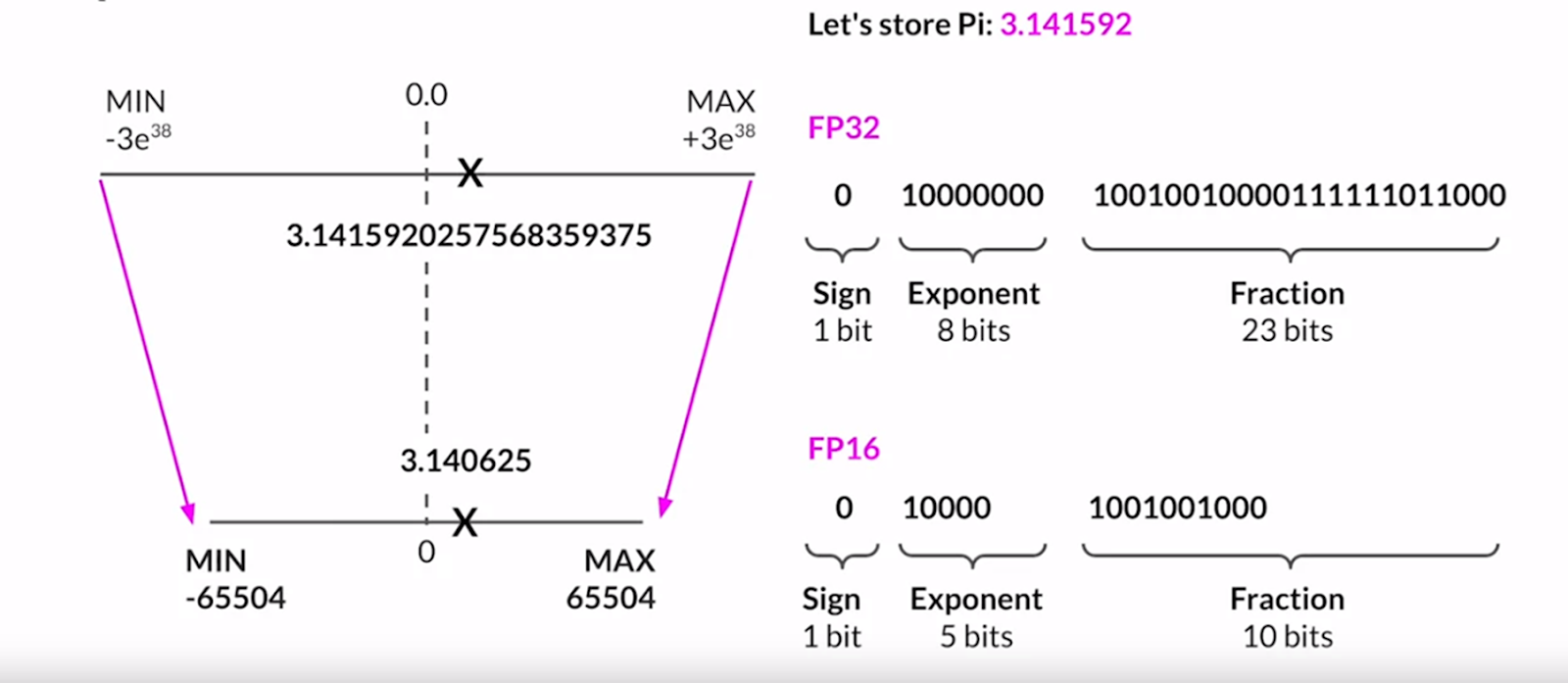
For example – if we have to store the value of Pi in 32-bit floating point precision, it would be 3.141592
Now instead of storing in 32-bit floating point precision, can we store in 16-bit floating point precision to reduce memory footprint?
When we store in 16-bit floating point precision
1 bit is for sign
5 bits are for exponent, and
And the remaining 10 bits are to store the fraction.
In 16-bit floating point precision, the value of Pi would be 3.140625.
The value has deviated a little and hence with a 16-bit floating point, the accuracy/ performance will drop slightly.
However, the memory required is reduced by half.
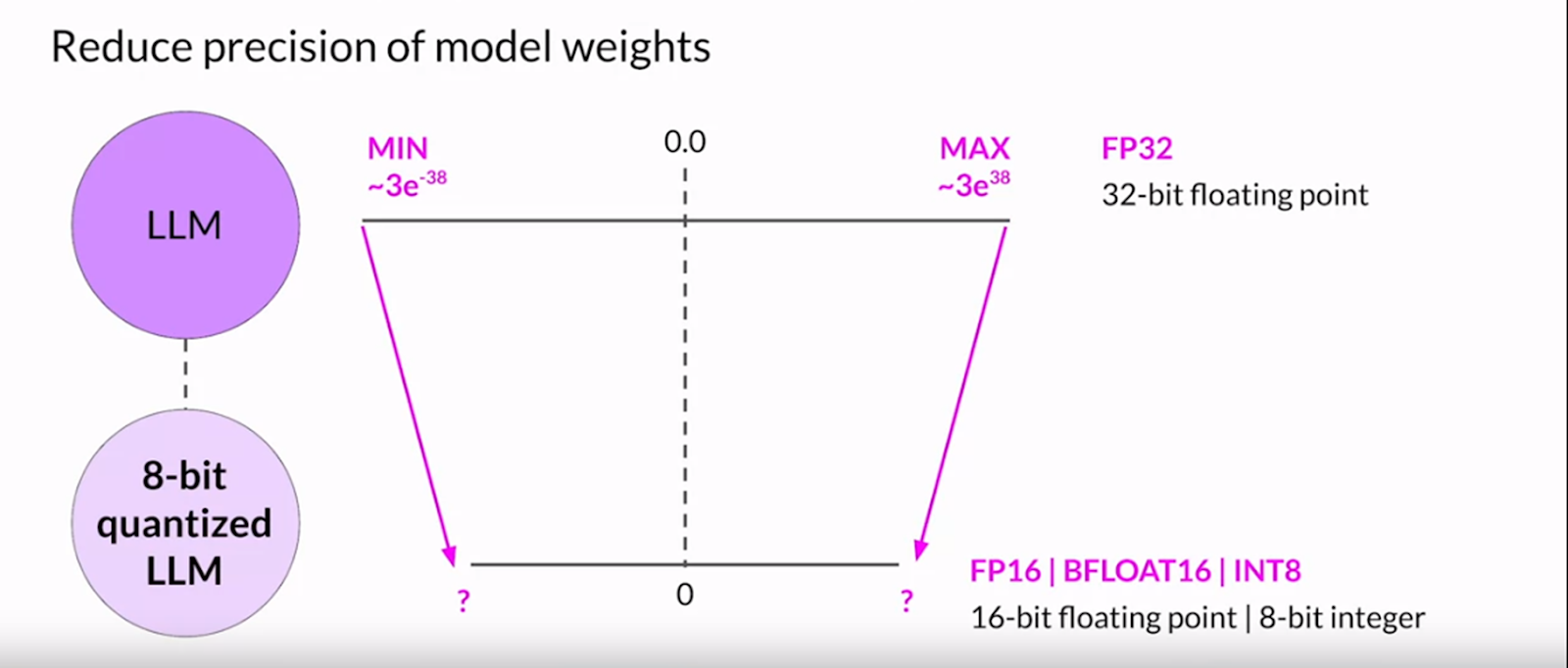
This is what quantization does, it reduces the computational requirement with a slight decrease in performance
So, if we are ok with this trade-off, Quantization is a very useful technique while finetuning an LLM or inferring from an LLM.
There are 2 models of Quantization
Post Training Quantization
In post-training quantization, the model’s weights are compressed after the training. The technique is used when we have to deploy or run the model in a resource-constrained environment.
Quantization Aware Training
In Quantized aware training, the model’s weights are compressed during training itself. This helps the model to learn the compressed representation in the training itself.
However, this could increase the training complexity.
Conclusion
Quantization helps us to use the LLMs with less computation power. If you have computational constraints and are ok with its slight drop in performance and accuracy, then the quantizing model would be a good choice.
Nowadays, even the 1-bit quantization technique has also evolved.
We can run 1-bit quantized models on our laptop as well and develop an RAG system for the documents stored on our device.
AI + Gen AI Course for working IT Professionals
In case you are looking to learn AI + Gen AI in an instructor-led live class environment, check out these dedicated courses for senior IT professionals here
Disclaimer – The images are taken from Deep Learning AI’s course We are just using it for educational purposes. No copyright infringement is intended. In case any part of content belongs to you or someone you know, please contact us and we will give you credit or remove your content.
Post Views:567
Share it with your senior IT friends and colleagues