Share it with your senior IT friends and colleagues
Reading Time: 6minutes
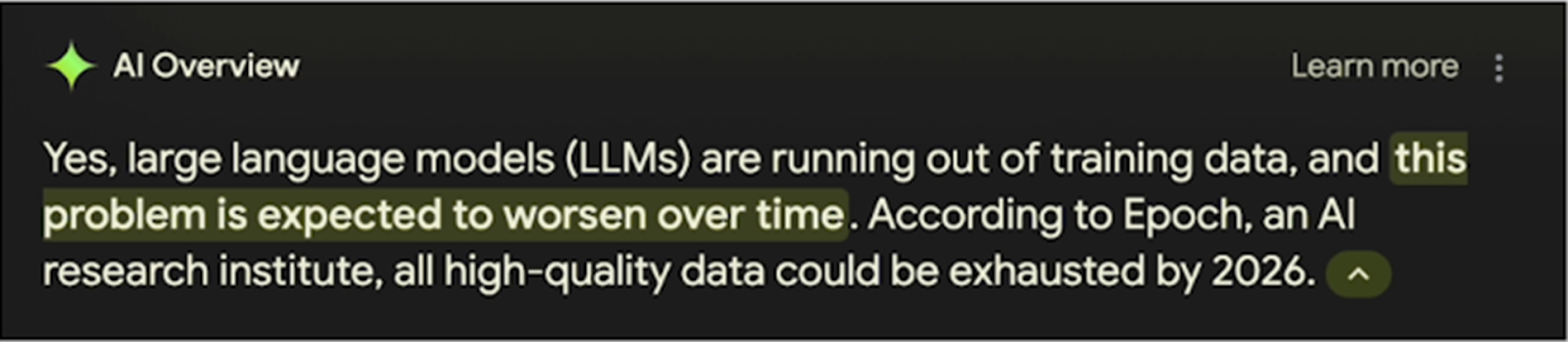
LLM makers are running out of training data.
Llama3 was pre-trained on 15 trillion tokens, almost 7 times more than Llama2.
To further increase LLM’s capabilities, we need more data but the problem is current training sets seem close to using all available high-quality English language text.
If we push further, we could get around 30 trillion data using all accessible sources. Adding non-English data, the upper limit is 60 trillion.
Even AI agrees with this
What’s after that?
The solution is Federated Learning where models are trained on locally distributed data instead of collecting data at a centralised place.
But we earlier said that data is limited, right?
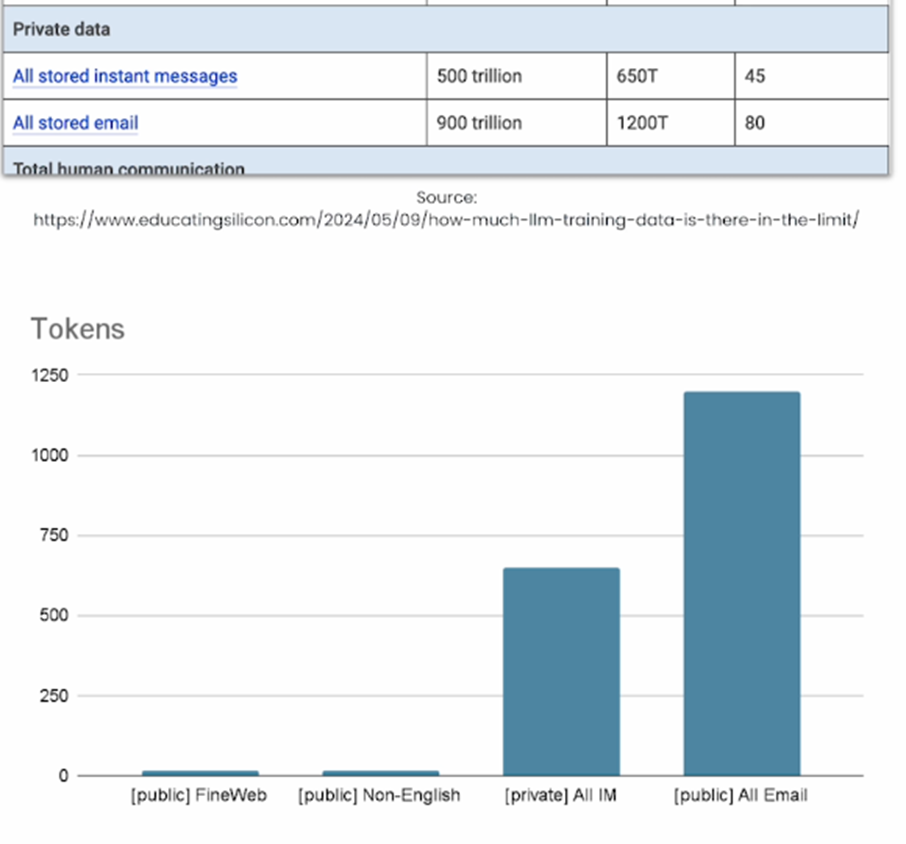
The public data is limited but private data is still untapped.
In the above figure, we can see that private data is much more than public data.
Federated learning can help us in remote training on locally distributed private data.
But with private data, comes privacy concerns.
Well, Federated learning helps models to train on data keeping Privacy intact.
In this article, we will understand more about the concept of Federated Learning and how privacy is maintained using differential privacy. Let’s dive in!
What is Federated Learning
As we started the article by answering “Why Federated Learning”, let us understand what exactly is it.
As per the definition
“Federated learning is a machine learning technique that enables multiple entities to collaborate on training a model while keeping their data decentralized.
It’s a privacy-friendly approach that doesn’t require a central database to store sensitive data.”
The traditional approach requires collecting all the training data at a central location.
However, most data is distributed across multiple organizations (like Healthcare, Government, Finance, Manufacturing, etc.) and multiple devices (like Phones, Laptops, Automotive, Home robotics, etc.)
So, instead of bringing data to training, can we bring training to data?
How does Federated Learning solve the problem?
In federated learning, training is done on a premise where the data is present.
It solves multiple problems, like
Data does not have to move (Sometimes it is very difficult to move the data because of a variety of reasons)
Privacy concerns
Regulations
How Federated Learning is done?
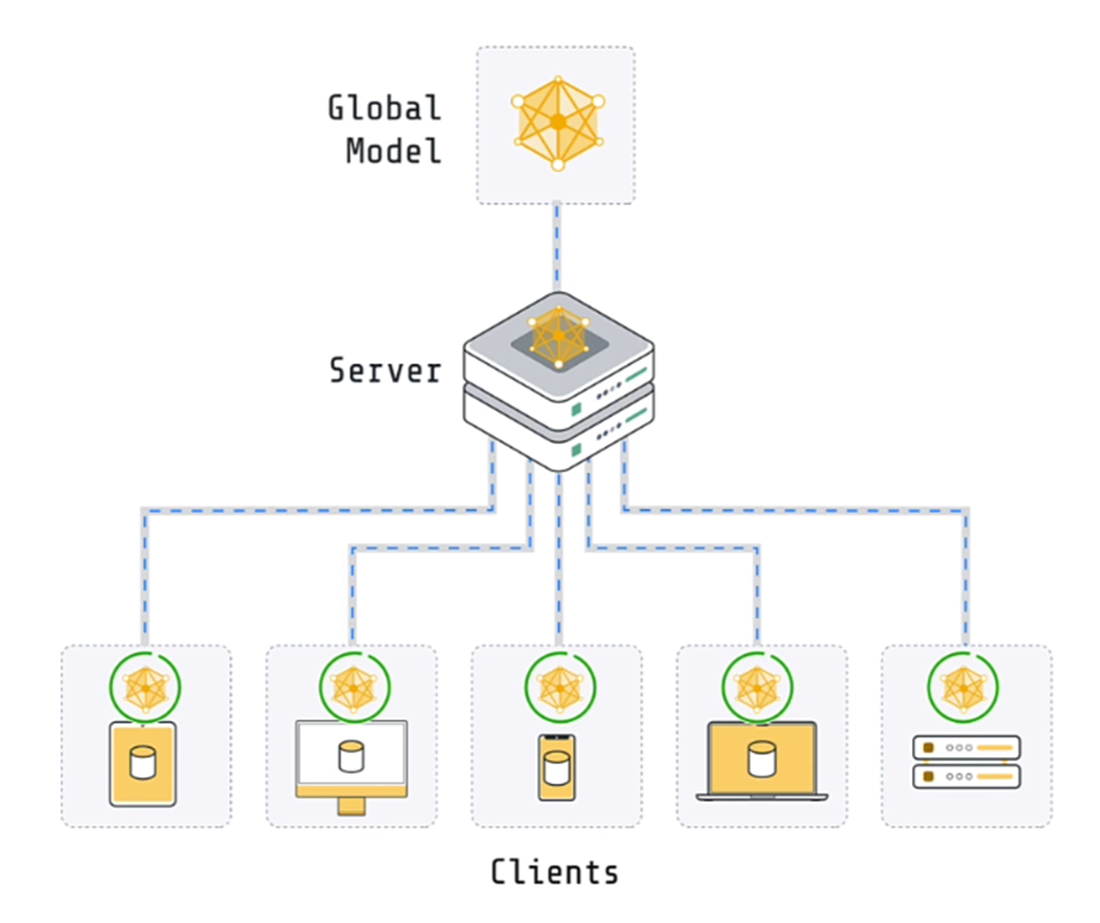
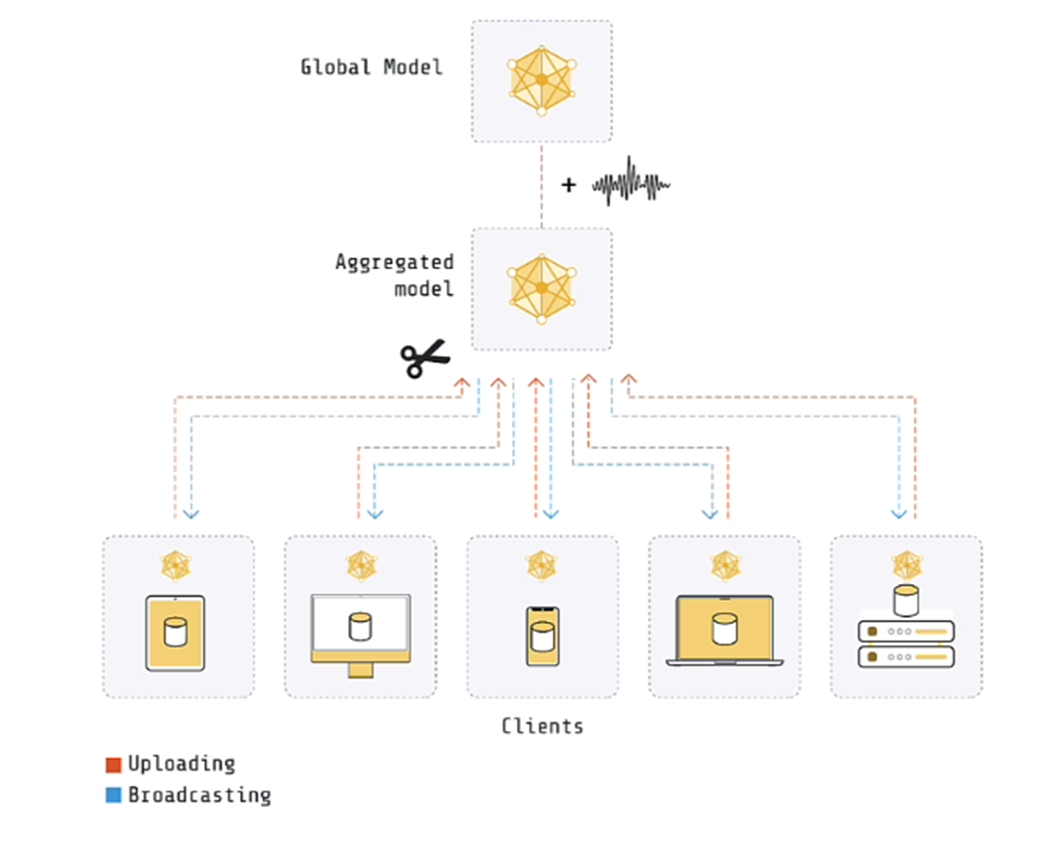
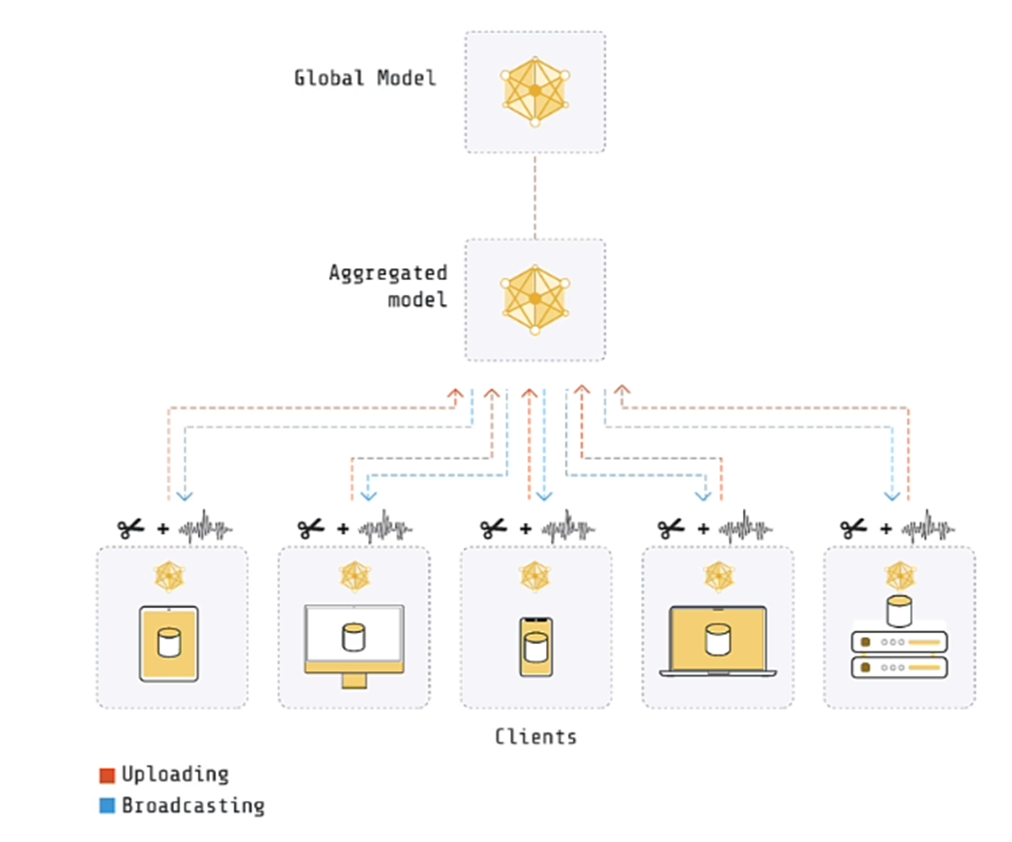
As per the above diagram, in this particular example, data is distributed over 5 clients.
There could be any number of clients in reality.
A separate training is done on each client for 1 epoch and the weights are then passed to the server where the aggregation happens.
There are many methods of aggregation. One method is to average all the weights from the client.
The server does not have any data. It just consolidates the training weights and coordinates the training across all clients.
Both the server and the clients have a copy of the model. The model on the server is known as the Global model while on the client is known as the local model.
In the next round, the average weights are passed to each client and then the next round of training happens.
This process continues till the full convergence criteria are met and loss is minimal.
You got the gist, right?
Training locally and then consolidation at a central level, then weights are transferred back to local client and the cycle continues till we have our loss minimum.
How to select the number of clients in Federated Learning?
It is not necessary to select all the clients. In the above example, we could have selected 3 or 4 clients at a time.
There could be a case that we have thousands of clients. In this case, we should not select all the clients but a sub-set i.e. a few hundred clients randomly.
Data also shows that more no. of clients provide diminishing returns.
How to handle privacy in Federated Learning?
I know what you are thinking, what about privacy?
Yes, you are right, privacy is the biggest concern in federated learning.
There is no sharing of data taking place in Federated learning. However, sharing & updation of weights can potentially leak the private data
Privacy attacks can be at 3 levels:
Client
Server
Third-Party
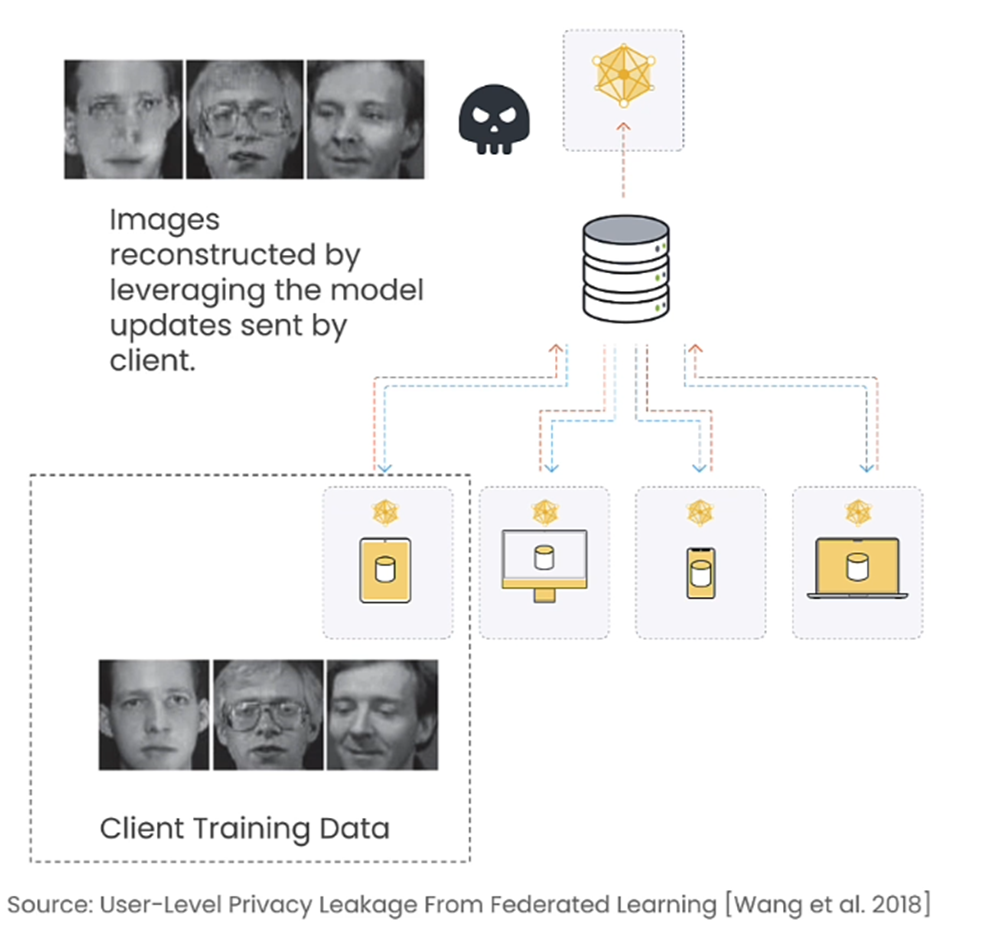
One common type of attack is the Data Reconstruction Attack where Images provided at the client level were almost reconstructed at the server level.
Let us see how we can tackle the privacy concerns through Differential Privacy.
Differential Privacy
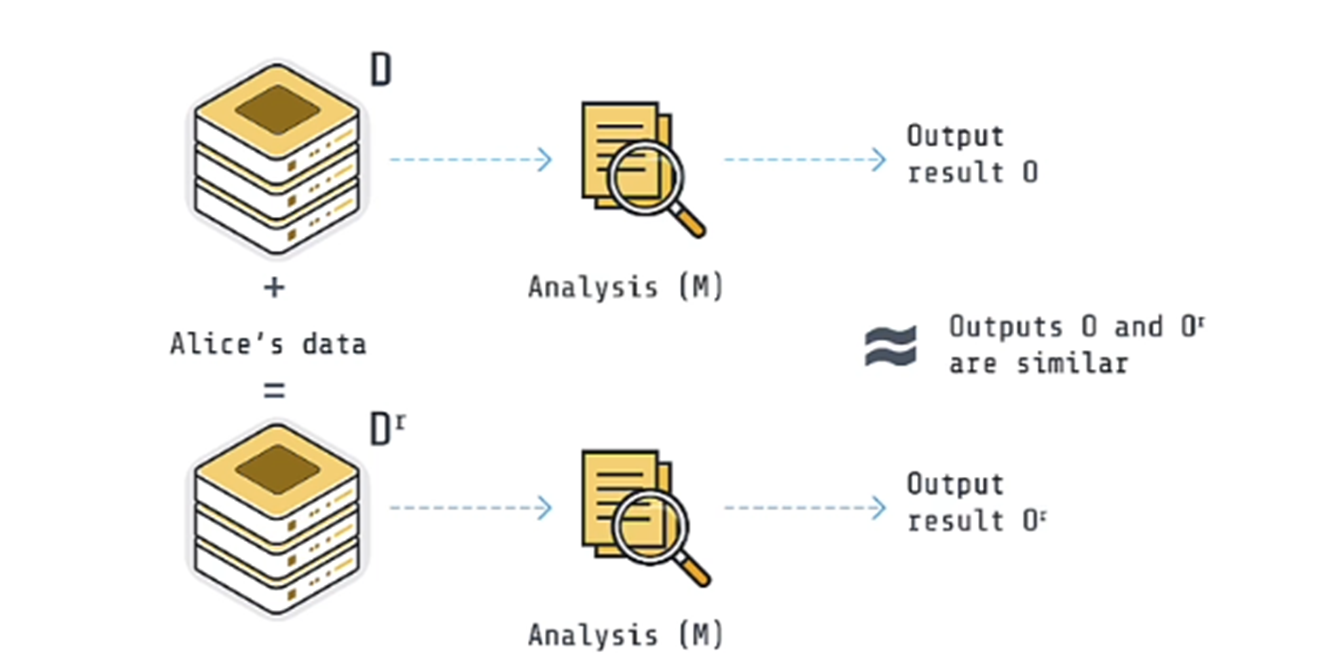
Differential Privacy obscures the individual data by adding some noise. What this essentially does is it makes individual entities inconsequential.
For example
Initially, we have a model D and then we add 1 specific data point of Alice, the output from both the models would be almost the same.
This makes adding Alice’s data inconsequential and hence there is no privacy breach. Both the models are basically indistinguishable.
There are 2 different ways to ensure Differential Privacy – Noise and Clipping
Noise – by adding noise to the data to make the output statistically indistinguishable.
Clipping – by removing the outliers and hence bounds the sensitivity
Differential Privacy can be done at 2 levels
1. Central Differential Privacy
In Cenreal Differential Privacy, the global server is responsible for adding noise to the globally aggregated parameters and clipping the weights.
The approach is that first, it should clip the weights sent by the client and then add calibrated noise.
2. Local Differential Privacy
In Local Differential Privacy, each local client is responsible for clipping the weights and adding the noise before sending it to the global server.
How much Bandwidth is required for Federated Learning?
So, we discussed multiple things related to Federated Learning. However, the question remains if we have to do Federated Learning then how much bandwidth is required?
Let us understand that through a simple formula
Formula =
(Model size out
Model size in)
* cohort zie * fraction selected * number of rounds
Here,
Model size out = size of the individual models that we are sending to the client
Model size in = size of the individual models that we are receiving from the client
Cohort size = total number of clients we have in our system
Fraction selected = what is the fraction of the total client size we have selected
Number of rounds = total number of training rounds.
Conclusion
As LLMs are becoming data guzzlers, they need more and more data for their training purposes. However, there is a limit to high quality publicly available data.
To get more data, we have to rely on private data and this is where Federaed Learning helps us in training on private data by maintaining privacy.
Dedicated AI + LLM Coaching for Senior IT Professionals
In case you are looking to learn AI + Gen AI in an instructor-led live class environment, check out these dedicated courses for senior IT professionals here
Disclaimer – The images are taken from Deep Learning AI’s course We are just using it for educational purposes. No copyright infringement is intended. In case any part of content belongs to you or someone you know, please contact us and we will give you credit or remove your content.
Post Views:76
Share it with your senior IT friends and colleagues